1
Introducing Universal-1
Last week we released Universal-1, a state-of-the-art multimodal speech recognition model. Universal-1 is trained on 12.5M hours of multilingual audio data, yielding impressive performance across the four key languages for which it was trained - English, Spanish, German, and French.
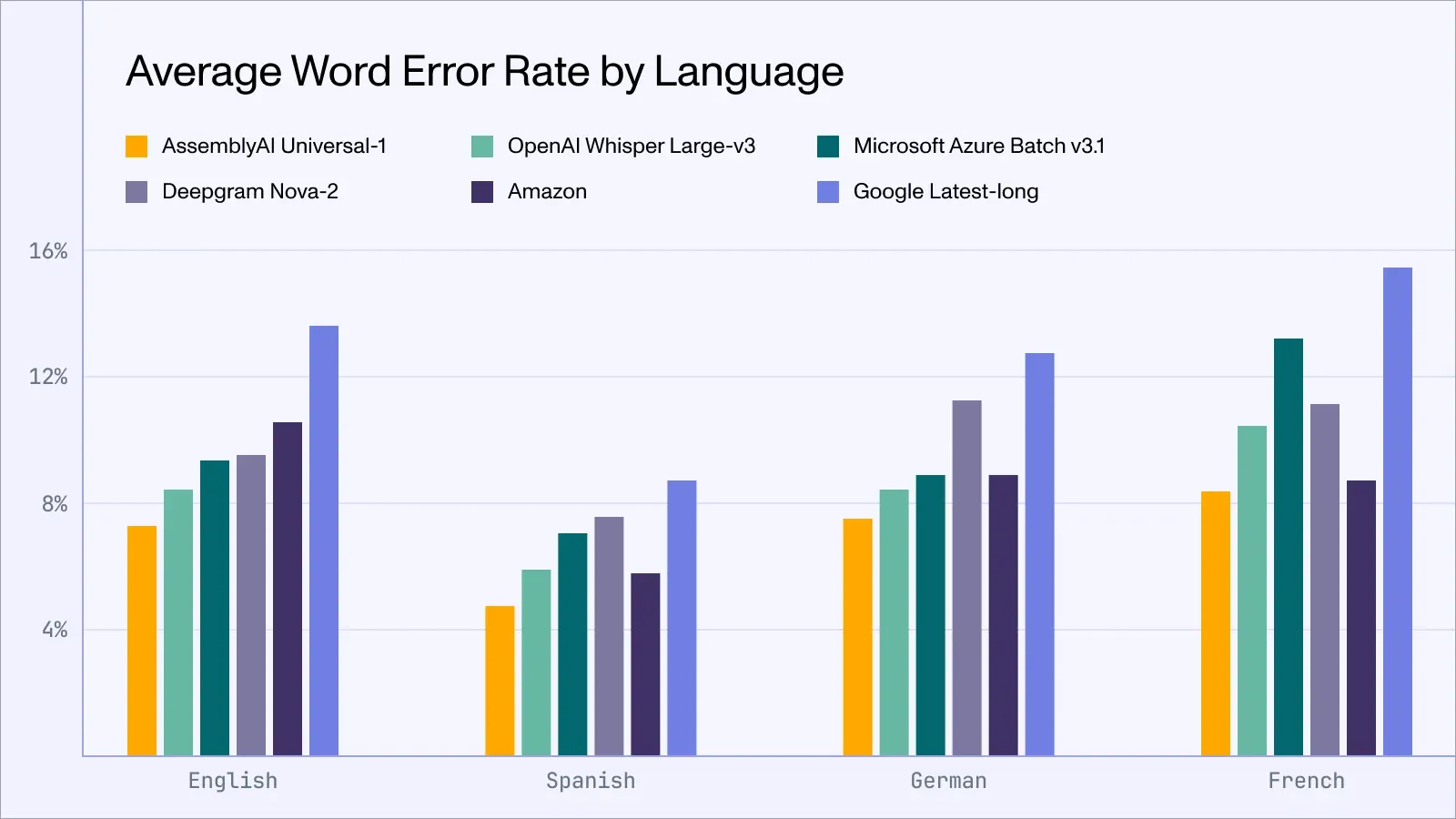
Universal-1 is now the default model for English and Spanish audio files sent to our v2/transcript endpoint for async processing, while German and French will be rolled out in the coming weeks.
You can read more about Universal-1 in our announcement blog or research blog, or you can try it out now on our Playground.