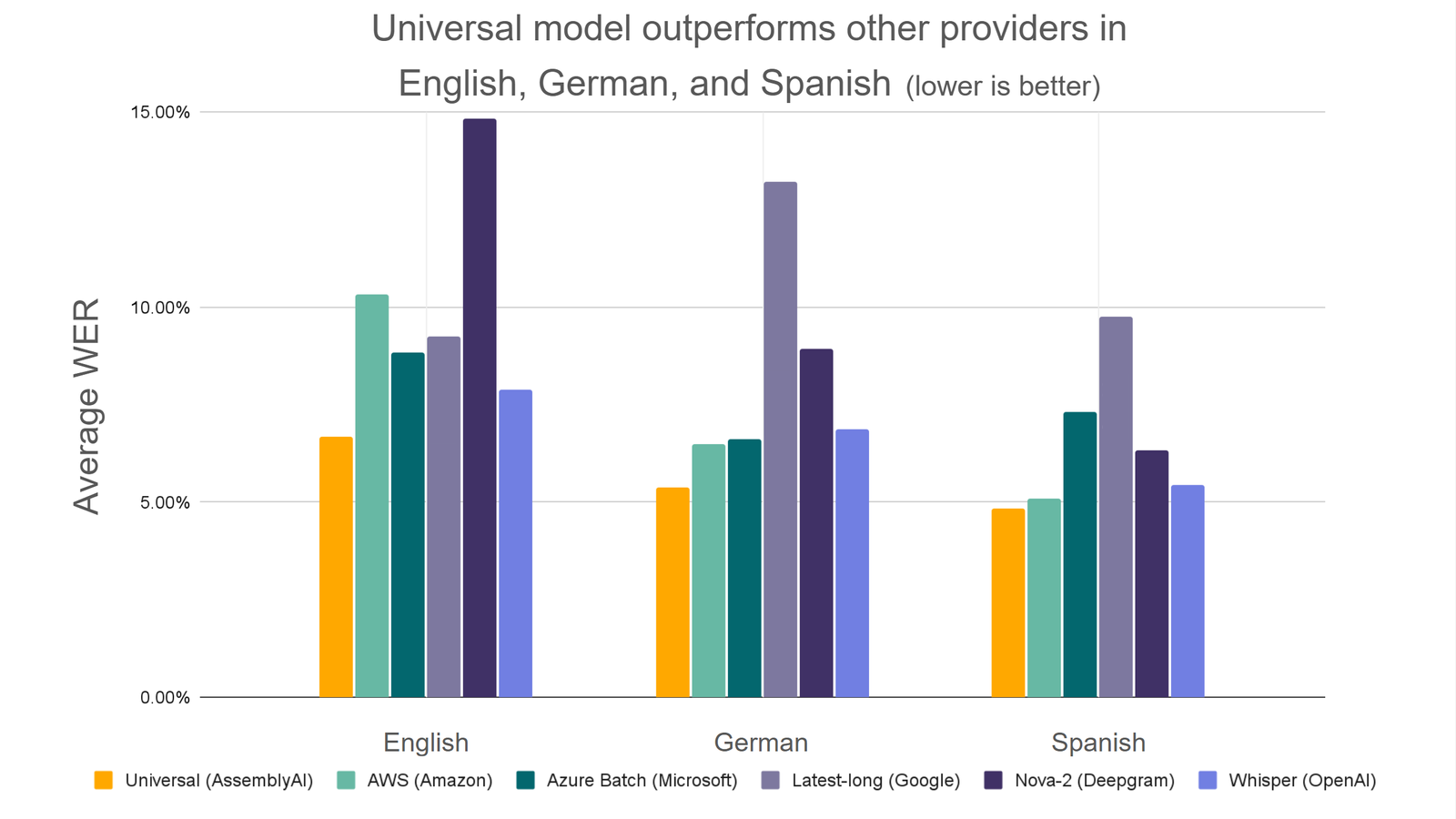
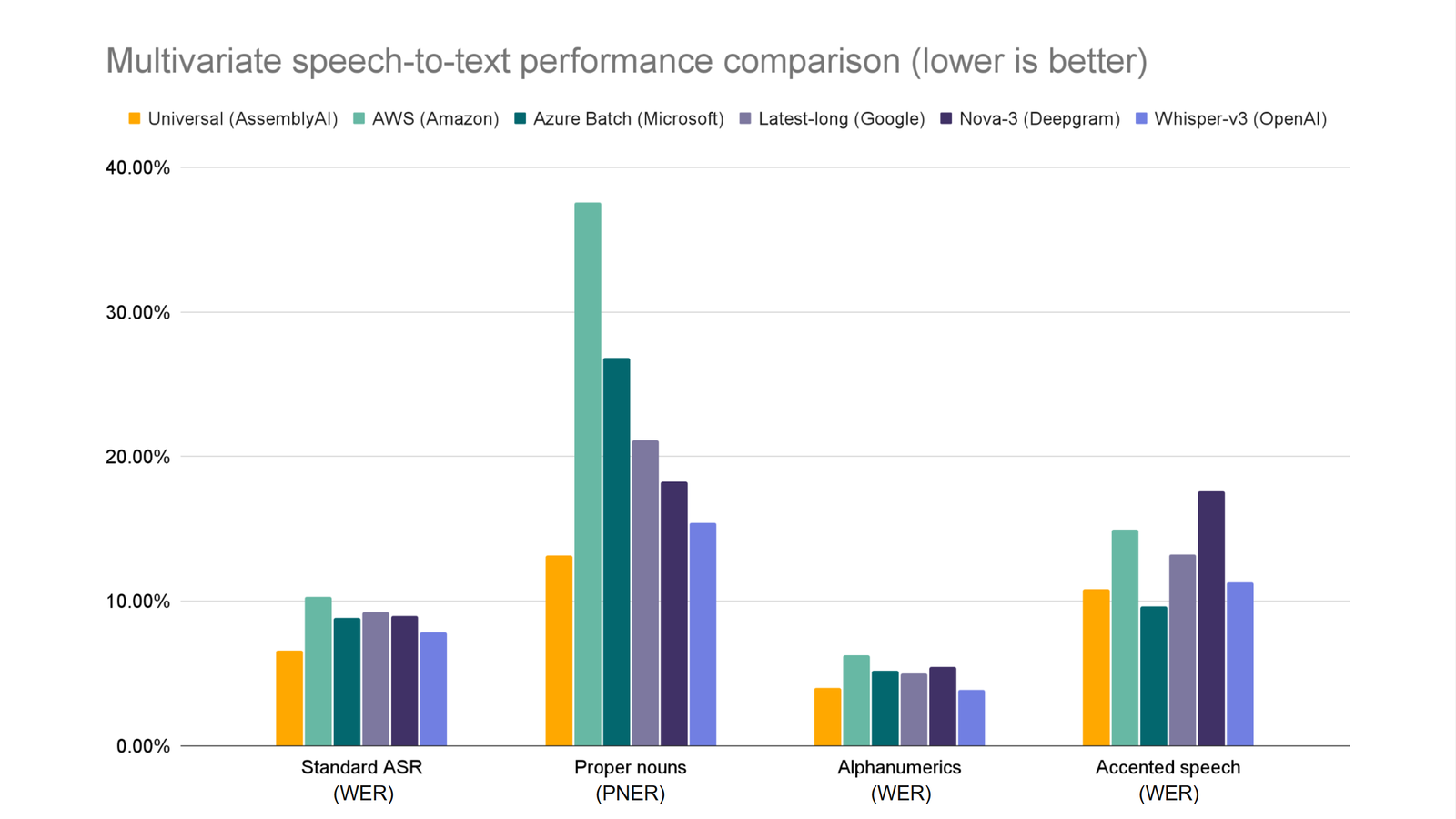
1
Dashboard Revamp
We have upgraded our dashboard—now with enhanced analytics and improved navigation to help you get more out of your AssemblyAI account.
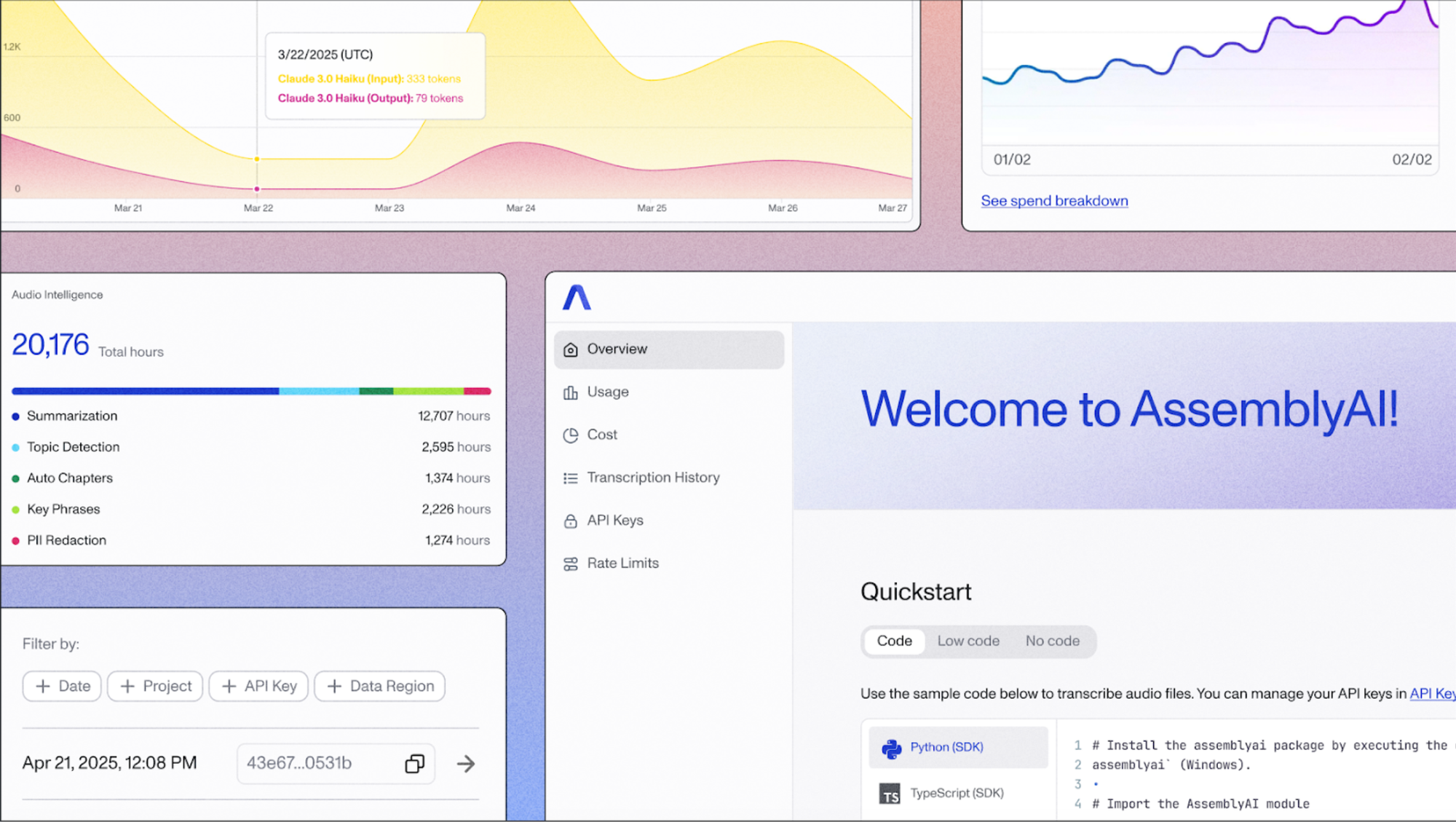
The new dashboard features:
- Modern UI with improved navigation and streamlined onboarding
- Enhanced analytics with usage and model-specific filtering
- Advanced transcription history with filtering by date, ID, project, and API key
- Dedicated rate limits section showing your account's limits for all endpoints
- Clearer billing information with improved plan details and usage visualization
Our multiple API keys feature is fully integrated with the new dashboard, allowing you to better organize projects and enhance security.
Log in to your AssemblyAI account today to experience the improved interface.