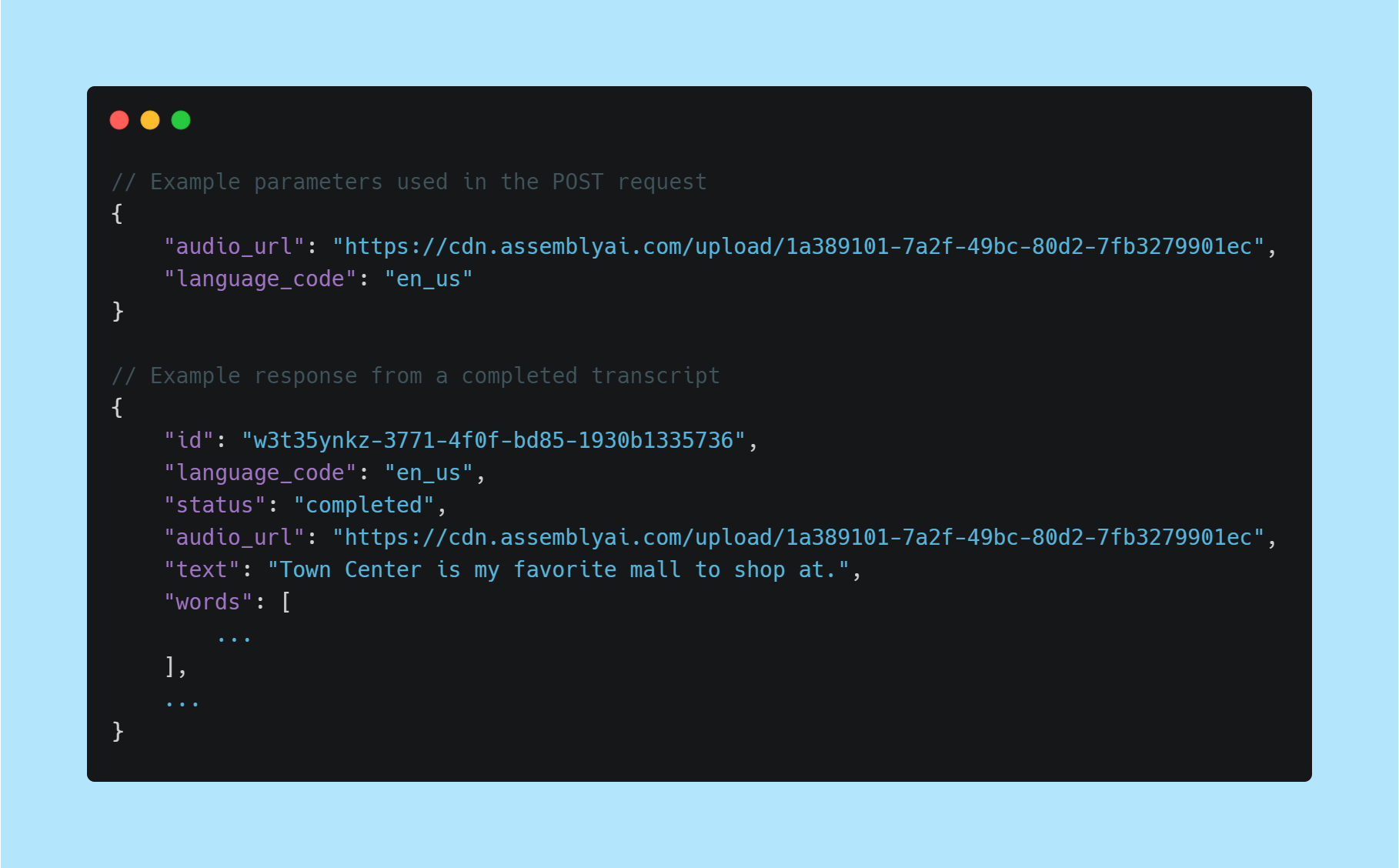
Added a new language_code parameter when making requests to /v2/transcript.
Developers can set this to en_us, en_uk, and en_au, which will ensure the correct English spelling is used - British English, Australian English, or US English (Default).
Quick note: for customers that were historically using the assemblyai_en_au or assemblyai_en_uk acoustic models, the language_code parameter is essentially redundant and doesn't need to be used.
Fixed an edge-case where some files with prolonged silences would occasionally have a single word predicted, such as "you" or "hi."
1
New Language Code Parameter for English Spelling
Added a new language_code parameter when making requests to /v2/transcript.
Developers can set this to en_us, en_uk, and en_au, which will ensure the correct English spelling is used - British English, Australian English, or US English (Default).
Quick note: for customers that were historically using the assemblyai_en_au or assemblyai_en_uk acoustic models, the language_code parameter is essentially redundant and doesn't need to be used.
Fixed an edge-case where some files with prolonged silences would occasionally have a single word predicted, such as "you" or "hi."
1
New Features Coming Soon, Bug Fixes
This week, our engineering team has been hard at work preparing for the release of exciting new features like:
Chapter Detection: Automatically summarize audio and video files into segments (aka "chapters").
Sentiment Analysis: Determine the sentiment of sentences in your transcript as "positive", "negative", or "neutral".
Disfluencies: Detects filler-words like "um" and "uh".
Improved average real-time latency by 2.1% and p99 latency by 0.06%.
Fixed an edge-case where confidence scores in the utterances category for dual-channel audio files would occasionally receive a confidence score greater than 1.0.
1
New Features Coming Soon, Bug Fixes
This week, our engineering team has been hard at work preparing for the release of exciting new features like:
Chapter Detection: Automatically summarize audio and video files into segments (aka "chapters").
Sentiment Analysis: Determine the sentiment of sentences in your transcript as "positive", "negative", or "neutral".
Disfluencies: Detects filler-words like "um" and "uh".
Improved average real-time latency by 2.1% and p99 latency by 0.06%.
Fixed an edge-case where confidence scores in the utterances category for dual-channel audio files would occasionally receive a confidence score greater than 1.0.
1
Improved v8 Model Processing Speed
Improved the API's ability to handle audio/video files with a duration over 8 hours.
Further improved transcription processing times by 12%.
Fixed an edge case in our responses for dual channel audio files where if speaker 2 interrupted speaker 1, the text from speaker 2 would cause the text from speaker 1 to be split into multiple turns, rather than contextually keeping all of speaker 1's text together.