1
v9 Transcription Model Released
We are happy to announce the release of our most accurate Speech Recognition model to date - version 9 (v9). This updated model delivers increased performance across many metrics on a wide range of audio types.
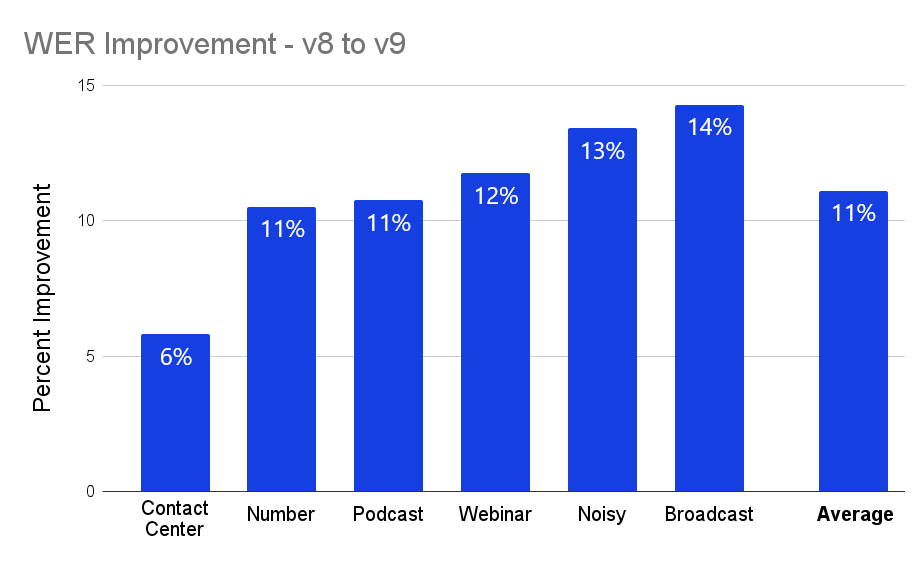
Word Error Rate, or WER, is the primary quantitative metric by which the performance of an automatic transcription model is measured. Our new v9 model shows significant improvements across a range of different audio types, as seen in the chart below, with a more than 11% improvement on average.
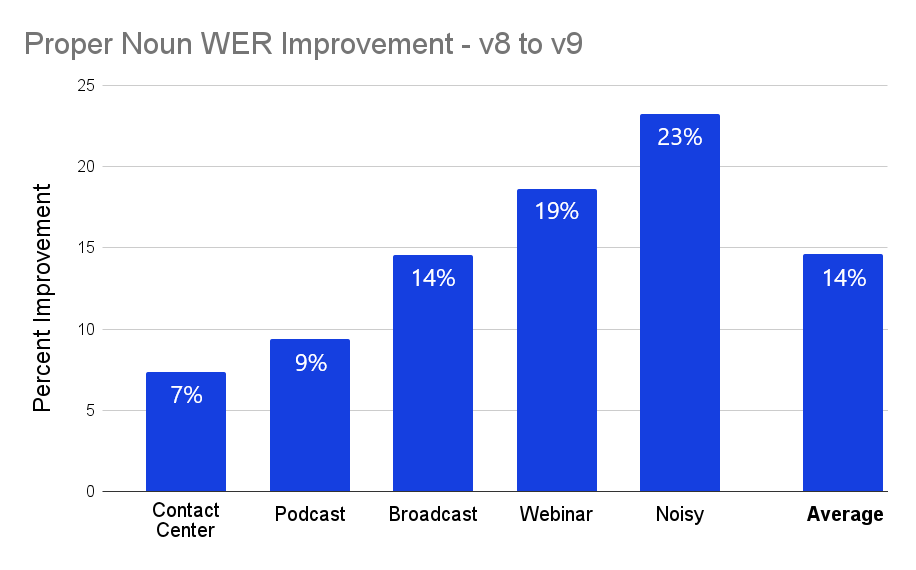
In addition to standard overall WER advancements, the new v9 model shows marked improvements with respect to proper nouns. In the chart below, we can see the relative performance increase of v9 over v8 for various types of audio, with a nearly 15% improvement on average.
The new v9 transcription model is currently live in production. This means that customers will see improved performance with no changes required on their end. The new model will automatically be used for all transcriptions created by our /v2/transcript endpoint going forward, with no need to upgrade for special access.
While our customers enjoy the elevated performance of the v9 model, our AI research team is already hard at work on our v10 model, which is slated to launch in early 2023. Building upon v9, the v10 model is expected to radically improve the state of the art in speech recognition.
Try our new v9 transcription model through your browser using the AssemblyAI Playground. Alternatively, sign up for a free API token to test it out through our API, or schedule a time with our AI experts to learn more.