Shorter Summaries Added to Auto Chapters, Improved Filler Word Detection
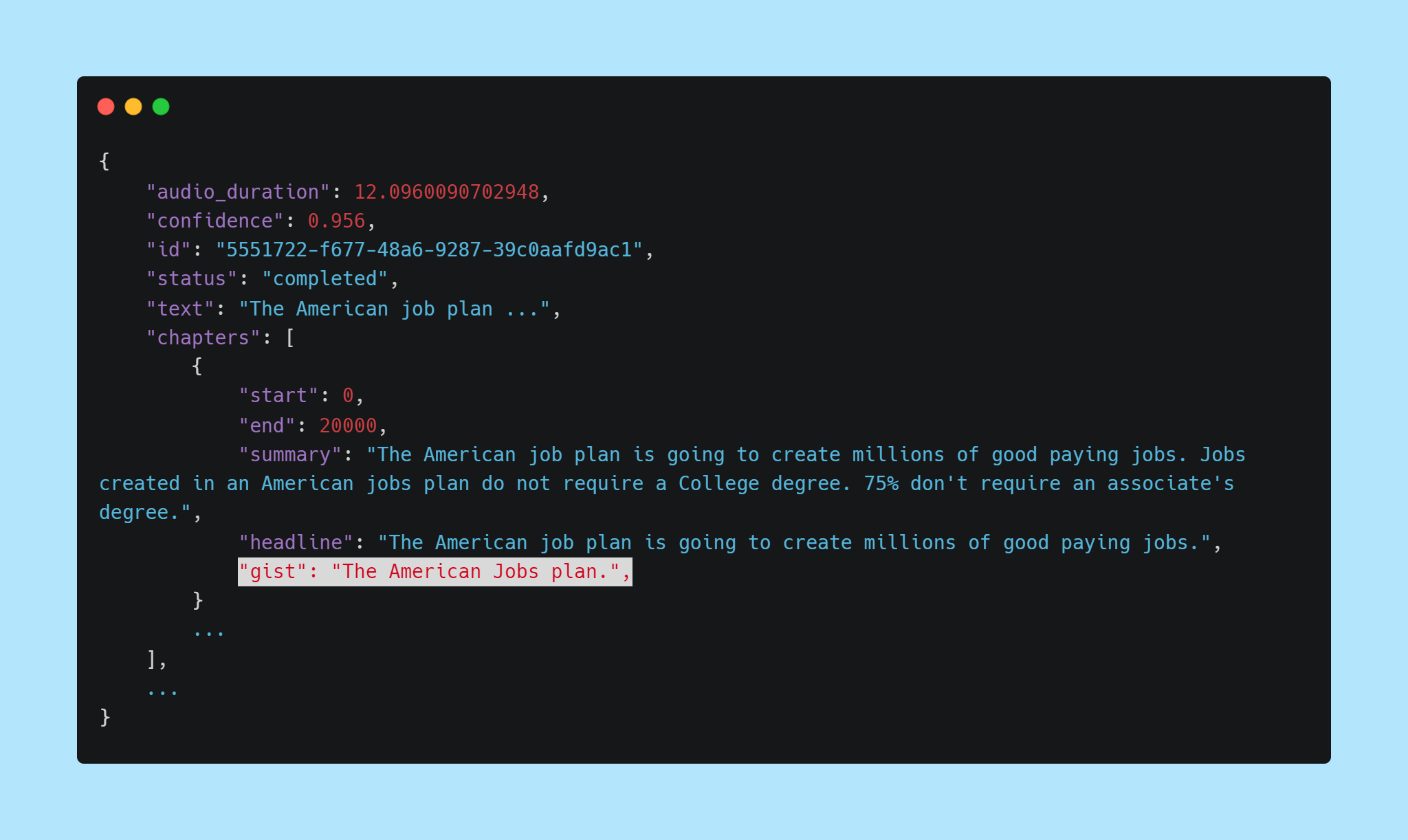
Added a new gist key to the Auto Chapters feature. This new key provides an ultra-short, usually 3 to 8 word summary of the content spoken during that chapter.
Implemented profanity filtering into Auto Chapters, which will prevent the API from generating a summary, headline, or gist that includes profanity.
Improved Filler Word (aka, disfluencies) detection by ~5%.
Improved accuracy for Real-Time Streaming Transcription.
Fixed an edge case where WebSocket connections for Real-Time Transcription sessions would occasionally not close properly after the session was terminated. This resulted in the client receiving a 4031 error code even after sending a session termination message.
Corrected a bug that occasionally attributed disfluencies to the wrong utterance when Speaker Labels or Dual-Channel Transcription was enabled.
1
Shorter Summaries Added to Auto Chapters, Improved Filler Word Detection
Added a new gist key to the Auto Chapters feature. This new key provides an ultra-short, usually 3 to 8 word summary of the content spoken during that chapter.
Implemented profanity filtering into Auto Chapters, which will prevent the API from generating a summary, headline, or gist that includes profanity.
Improved Filler Word (aka, disfluencies) detection by ~5%.
Improved accuracy for Real-Time Streaming Transcription.
Fixed an edge case where WebSocket connections for Real-Time Transcription sessions would occasionally not close properly after the session was terminated. This resulted in the client receiving a 4031 error code even after sending a session termination message.
Corrected a bug that occasionally attributed disfluencies to the wrong utterance when Speaker Labels or Dual-Channel Transcription was enabled.
1
v8.5 Asynchronous Transcription Model Released
Our Asynchronous Speech Recognition model is now even better with the release of v8.5.
This update improves overall accuracy by 4% relative to our v8 model.
This is achieved by improving the model’s ability to handle noisy or difficult-to-decipher audio.
The v8.5 model also improves Inverse Text Normalization for numbers.
1
v8.5 Asynchronous Transcription Model Released
Our Asynchronous Speech Recognition model is now even better with the release of v8.5.
This update improves overall accuracy by 4% relative to our v8 model.
This is achieved by improving the model’s ability to handle noisy or difficult-to-decipher audio.
The v8.5 model also improves Inverse Text Normalization for numbers.
1
New and Improved API Documentation
Launched the new AssemblyAI Docs, with more complete documentation and an easy-to-navigate interface so developers can effectively use and integrate with our API. Click here to view the new and improved documentation.
Added two new fields to the FinalTranscript response for Real-time Transcriptions. The punctuated key is a Boolean value indicating if punctuation was successful. The text_formatted key is a Boolean value indicating if Inverse Text Normalization (ITN) was successful.