1
Universal improvements
Last week we delivered improvements to our October 2024 Universal release across latency, accuracy, and language coverage.
Universal demonstrates the lowest standard error rate when compared to leading models on the market for English, German, and Spanish:
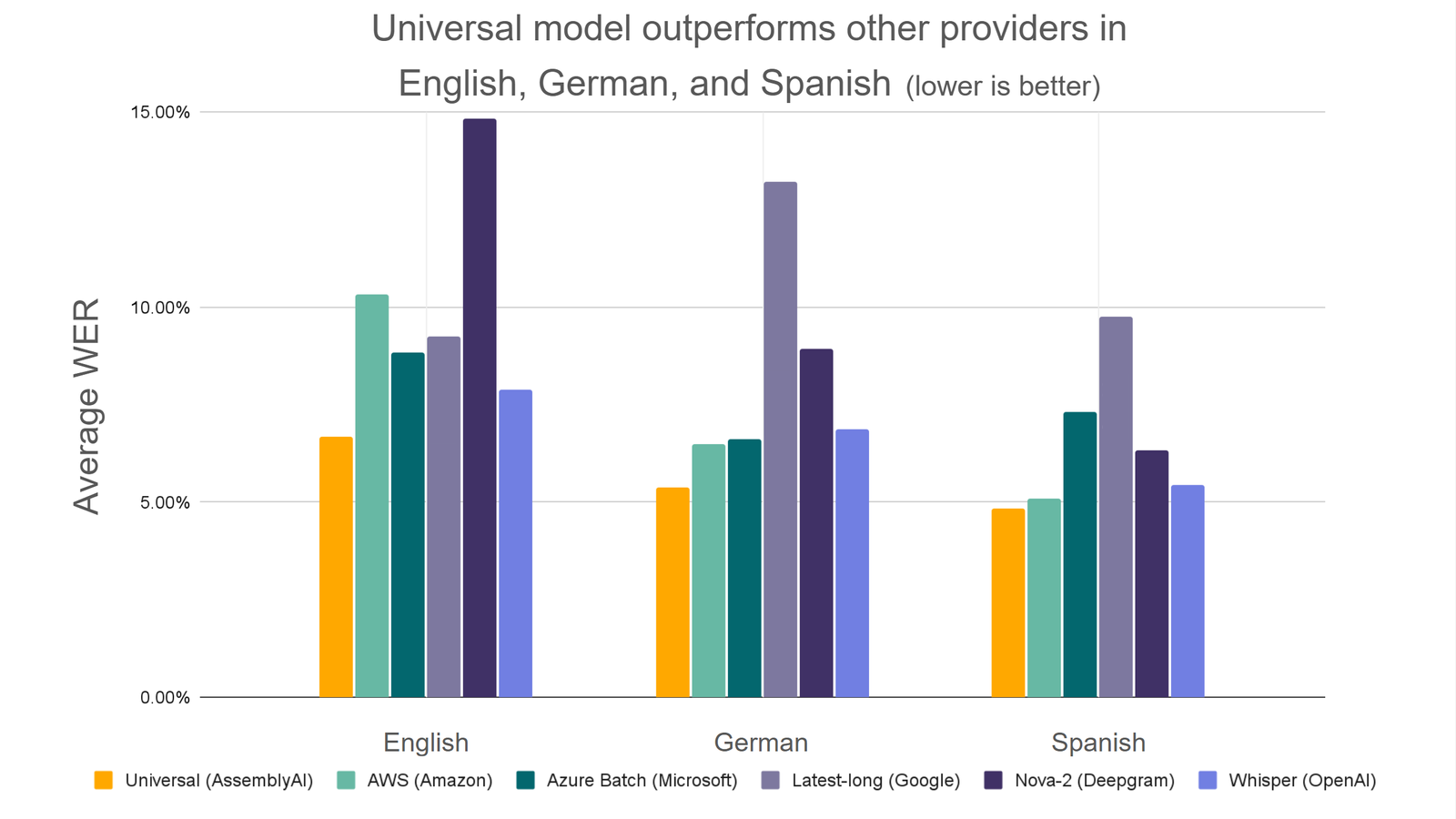
Additionally, these improvements to accuracy are accompanied by significant increases in processing speed. Our latest Universal release achieves a 27.4% speedup in inference time for the vast majority of files (at the 95th percentile), enabling faster transcription at scale.
Additionally, these changes build on Universal's already best-in-class English performance to bring significant upgrades to last-mile challenges, meaning that Universal faithfully captures the fine details that make transcripts useable, like proper nouns, alphanumerics, and formatting.
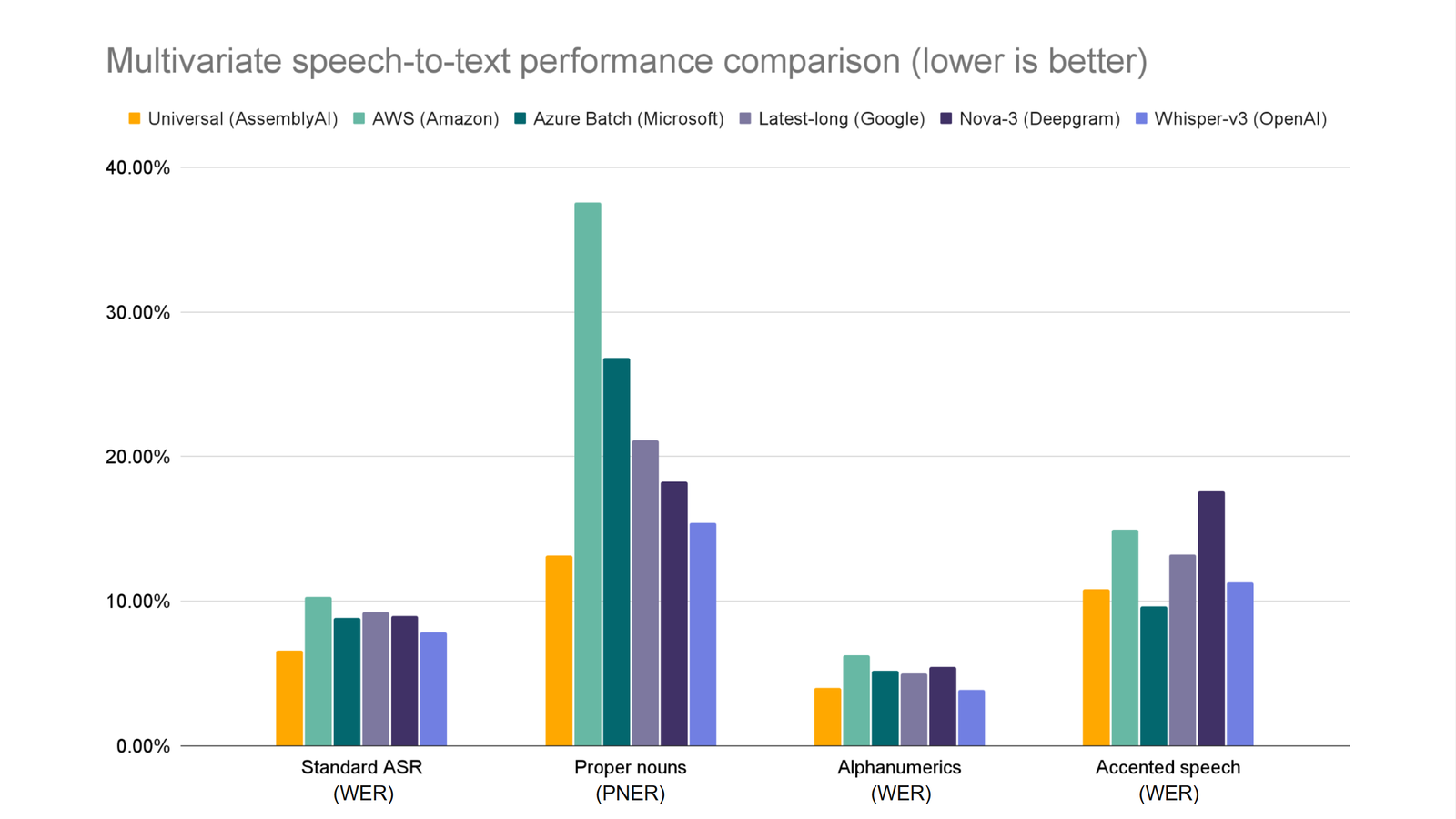
You can read our launch blog to learn more about these Universal updates.