1
Latency and cost reductions, concurrency increase
We introduced major improvements to our API’s inference latency, with the majority of audio files now completing in well under 45 seconds regardless of audio duration, with a Real-Time Factor (RTF) of up to .008.
To put an RTF of .008x into perspective, this means you can now convert a:
- 1h3min (75MB) meeting in 35 seconds
- 3h15min (191MB) podcast in 133 seconds
- 8h21min (464MB) video course in 300 seconds
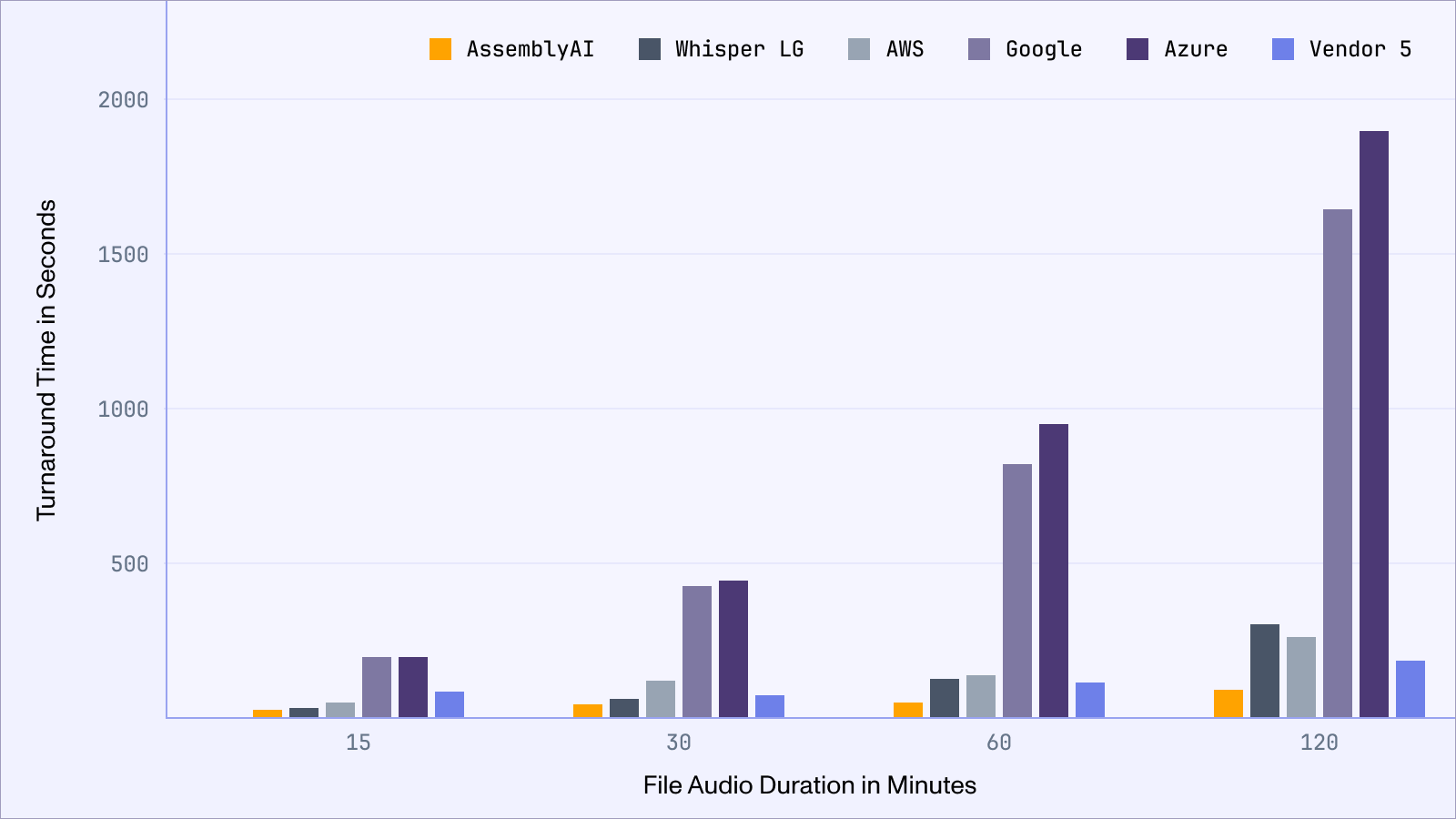
In addition to these latency improvements, we have reduced our Speech-to-Text pricing. You can now access our Speech AI models with the following pricing:
- Async Speech-to-Text for $0.37 per hour (previously $0.65)
- Real-time Speech-to-Text for $0.47 per hour (previously $0.75)
We’ve also reduced our pricing for the following Audio Intelligence models: Key Phrases, Sentiment Analysis, Summarization, PII Audio Redaction, PII Redaction, Auto Chapters, Entity Detection, Content Moderation, and Topic Detection. You can view the complete list of pricing updates on our Pricing page.
Finally, we've increased the default concurrency limits for both our async and real-time services. The increase is immediate for async, and will be rolled out soon for real-time. These new limits are now:
- 200 for async (up from 32)
- 100 for real-time (up from 32)
These new changes stem from the efficiencies that our incredible research and engineering teams drive at every level of our inference pipeline, including optimized model compilation, intelligent mini batching, hardware parallelization, and optimized serving infrastructure.
Learn more about these changes and our inference pipeline in our blog post.