We have increased the memory of our transcoding service workers, leading to a significant reduction in errors that say File does not appear to contain audio.
1
Fewer LeMUR 500 errors
We’ve made improvements to our LeMUR service to reduce the number of 500 errors.
We’ve made improvements to our real-time service, which provides a small increase to the accuracy of timestamps in some edge cases.
We have increased the usage limit for our free tier to 100 hours. New users can now use our async API to transcribe up to 100 hours of audio, with a concurrency limit of 5, before needing to upgrade their accounts.
We have rolled out the concurrency limit increase for our real-time service. Users now have access to up to 100 concurrent streams by default when using our real-time service.
Higher concurrency is available upon request with no limit to what our API can support. If you need a higher concurrency limit, please either contact our Sales team or reach out to us at support@assemblyai.com. Note that our real-time service is only available for upgraded accounts.
1
Latency and cost reductions, concurrency increase
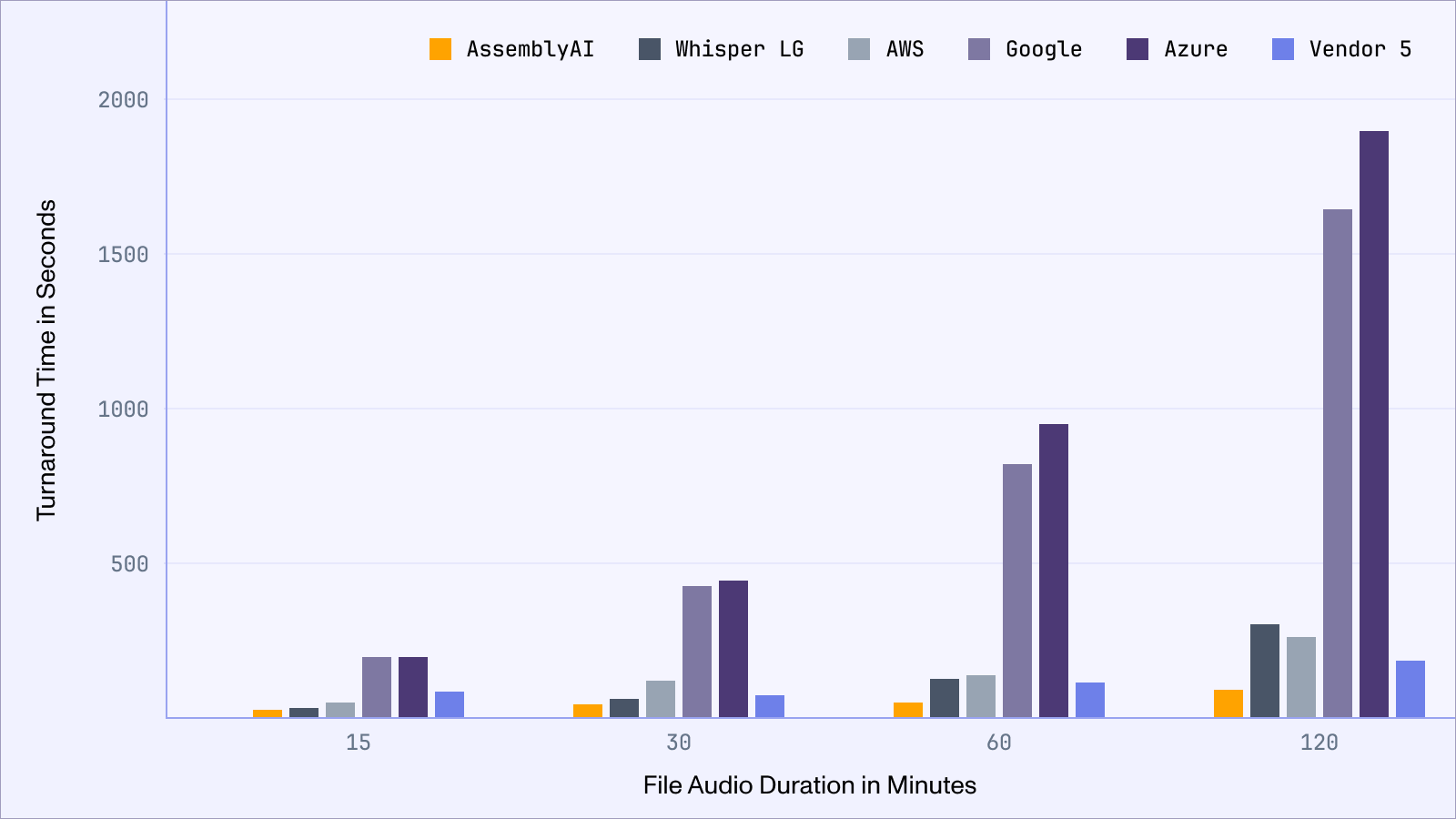
We introduced major improvements to our API’s inference latency, with the majority of audio files now completing in well under 45 seconds regardless of audio duration, with a Real-Time Factor (RTF) of up to .008.
To put an RTF of .008x into perspective, this means you can now convert a:
1h3min (75MB) meeting in 35 seconds
3h15min (191MB) podcast in 133 seconds
8h21min (464MB) video course in 300 seconds
In addition to these latency improvements, we have reduced our Speech-to-Text pricing. You can now access our Speech AI models with the following pricing:
Async Speech-to-Text for $0.37 per hour (previously $0.65)
Real-time Speech-to-Text for $0.47 per hour (previously $0.75)
We’ve also reduced our pricing for the following Audio Intelligence models: Key Phrases, Sentiment Analysis, Summarization, PII Audio Redaction, PII Redaction, Auto Chapters, Entity Detection, Content Moderation, and Topic Detection. You can view the complete list of pricing updates on our Pricing page.
Finally, we've increased the default concurrency limits for both our async and real-time services. The increase is immediate for async, and will be rolled out soon for real-time. These new limits are now:
200 for async (up from 32)
100 for real-time (up from 32)
These new changes stem from the efficiencies that our incredible research and engineering teams drive at every level of our inference pipeline, including optimized model compilation, intelligent mini batching, hardware parallelization, and optimized serving infrastructure.
Learn more about these changes and our inference pipeline in our blog post.
1
Claude 2.1 available through LeMUR
Anthropic’s Claude 2.1 is now generally available through LeMUR. Claude 2.1 is similar to our Default model and has reduced hallucinations, a larger context window, and performs better in citations.
Claude 2.1 can be used by setting the final_model parameter to anthropic/claude-2-1 in API requests to LeMUR. Here's an example of how to do this through our Python SDK:
import assemblyai as aai
transcriber = aai.Transcriber()
transcript = transcriber.transcribe("https://example.org/customer.mp3")
result = transcript.lemur.task(
"Summarize the following transcript in three to five sentences.",
final_model=aai.LemurModel.claude2_1,
)
print(result.response)
You can learn more about setting the model used with LeMUR in our docs.