Dual Channel Support for Conversational Summarization / Improved Timestamps
We’ve made updates to our Conversational Summarization model to support dual-channel files. Effective immediately, dual_channel may be set to True when summary_model is set to conversational.
We've made significant improvements to timestamps for non-English audio. Timestamps are now typically accurate between 0 and 100 milliseconds. This improvement is effective immediately for all non-English audio files submitted to AssemblyAI for transcription.
1
Improved Transcription Accuracy for Phone Numbers
We’ve made updates to our Core Transcription model to improve the transcription accuracy of phone numbers by 10%. This improvement is effective immediately for all audio files submitted to AssemblyAI for transcription.
We've improved scaling for our read-only database, resulting in improved performance for read-only requests.
1
v9 Transcription Model Released
We are happy to announce the release of our most accurate Speech Recognition model to date - version 9 (v9). This updated model delivers increased performance across many metrics on a wide range of audio types.
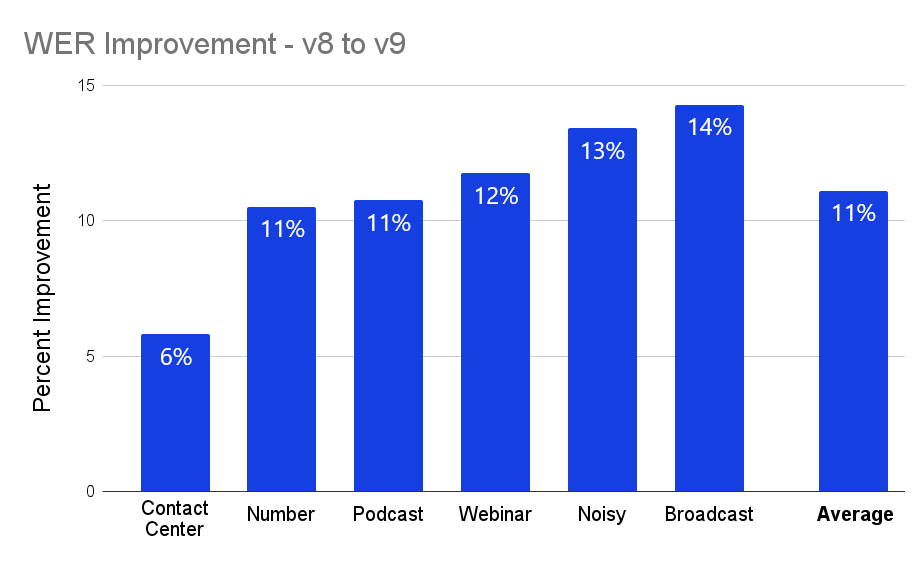
Word Error Rate, or WER, is the primary quantitative metric by which the performance of an automatic transcription model is measured. Our new v9 model shows significant improvements across a range of different audio types, as seen in the chart below, with a more than 11% improvement on average.
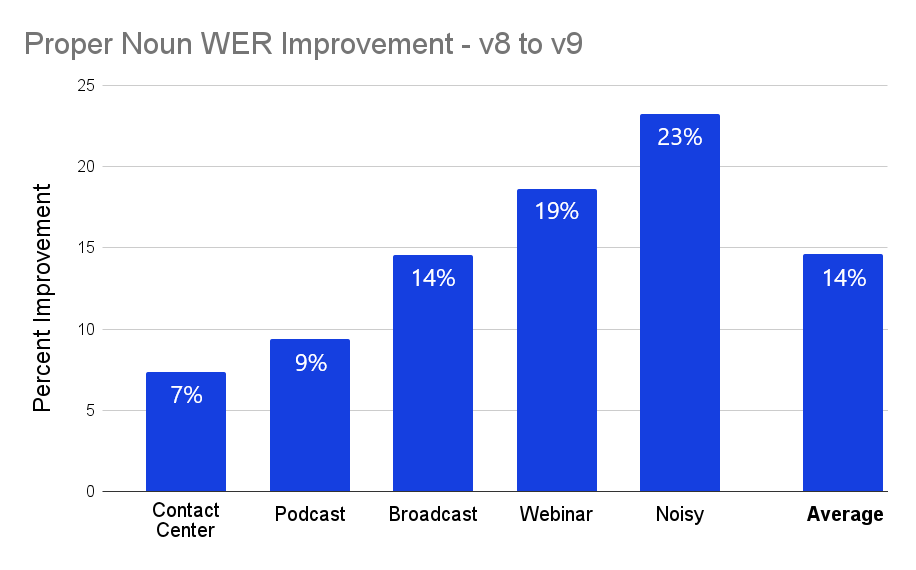
In addition to standard overall WER advancements, the new v9 model shows marked improvements with respect to proper nouns. In the chart below, we can see the relative performance increase of v9 over v8 for various types of audio, with a nearly 15% improvement on average.
The new v9 transcription model is currently live in production. This means that customers will see improved performance with no changes required on their end. The new model will automatically be used for all transcriptions created by our /v2/transcript endpoint going forward, with no need to upgrade for special access.
While our customers enjoy the elevated performance of the v9 model, our AI research team is already hard at work on our v10 model, which is slated to launch in early 2023. Building upon v9, the v10 model is expected to radically improve the state of the art in speech recognition.
Try our new v9 transcription model through your browser using the AssemblyAI Playground. Alternatively, sign up for a free API token to test it out through our API, or schedule a time with our AI experts to learn more.
1
New Summarization Models Tailored to Use Cases
We are excited to announce that new Summarization models are now available! Developers can now choose between multiple summary models that best fit their use case and customize the output based on the summary length.
The new models are:
Informative which is best for files with a single speaker, like a presentation or lecture
Conversational which is best for any multi-person conversation, like customer/agent phone calls or interview/interviewee calls
Catchy which is best for creating video, podcast, or media titles
Developers can use the summary_model parameter in their POST request to specify which of our summary models they would like to use. This new parameter can be used along with the existing summary_type parameter to allow the developer to customize the summary to their needs.
Check out our latest blog post to learn more about the new Summarization models or head to the AssemblyAI Playground to test Summarization in your browser!
1
Improved Transcription Accuracy for COVID
We’ve made updates to our Core Transcription model to improve the transcription accuracy of the word COVID. This improvement is effective immediately for all audio files submitted to AssemblyAI for transcription.
Static IP support for webhooks is now generally available!
Outgoing webhook requests sent from AssemblyAI will now originate from a static IP address 44.238.19.20, rather than a dynamic IP address. This gives you the ability to easily validate that the source of the incoming request is coming from our server. Optionally, you can choose to whitelist this static IP address to add an additional layer of security to your system.
See our walkthrough on how to start receiving webhooks for your transcriptions.