Entity Detection Released, Improved Filler Word Detection, Usage Alerts
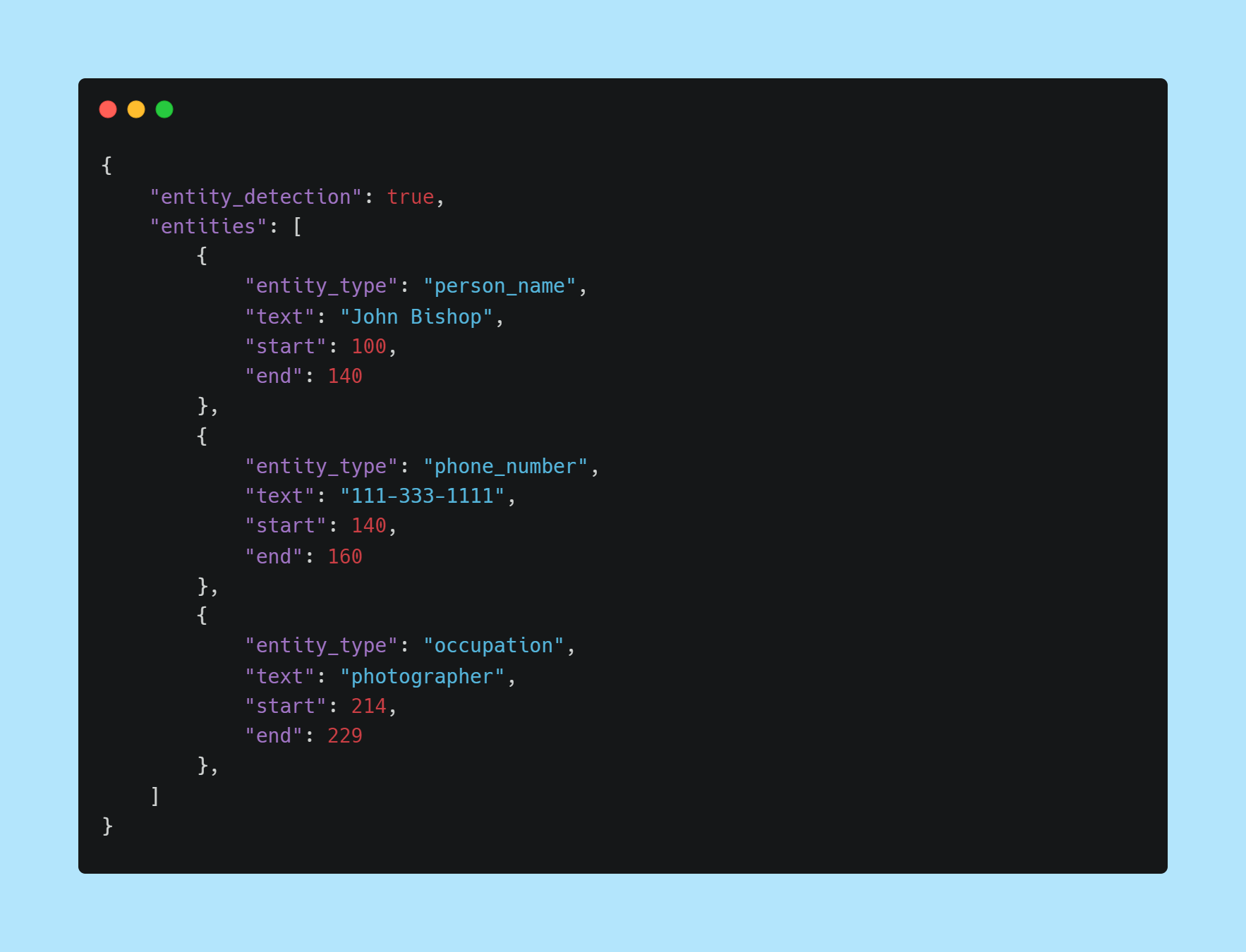
v1 release of Entity Detection - automatically detects a wide range of entities like person and company names, emails, addresses, dates, locations, events, and more.
To include Entity Detection in your transcript, set entity_detection to true in your POST request to /v2/transcript.
When your transcript is complete, you will see an entities key towards the bottom of the JSON response containing the entities detected, as shown here:
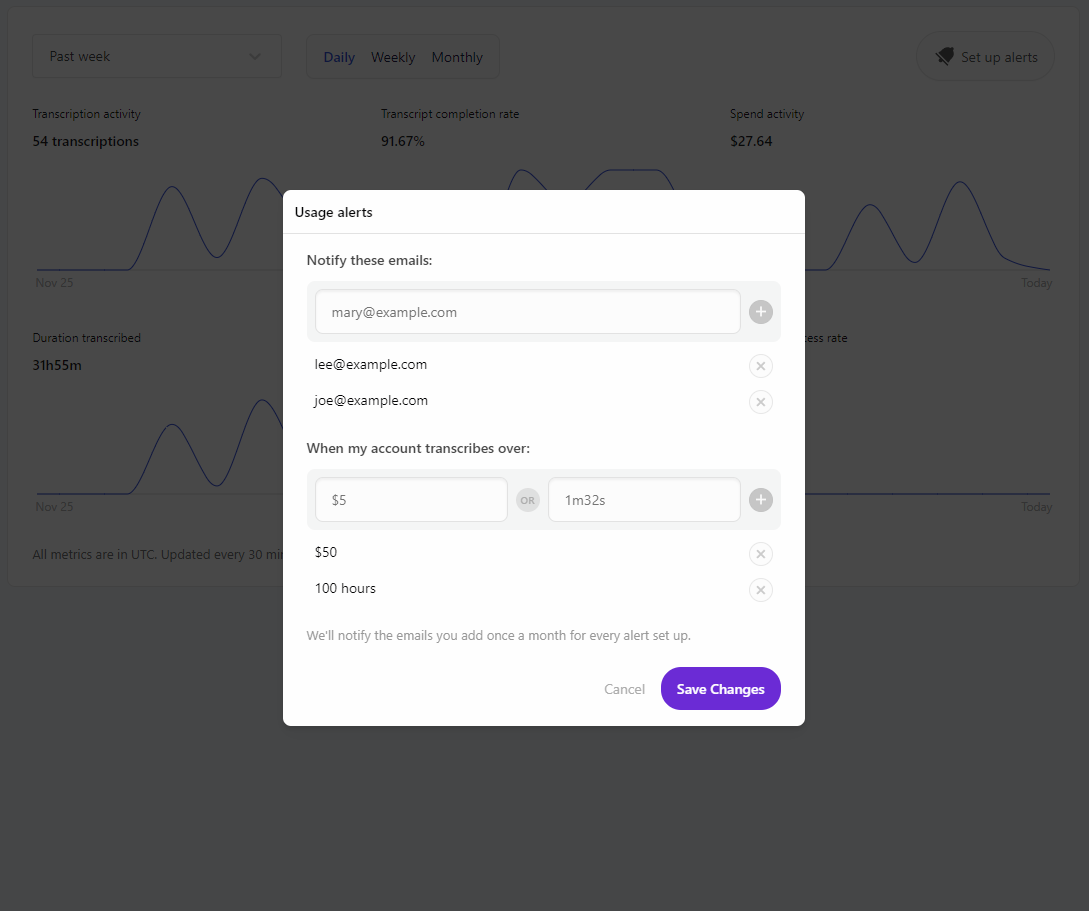
Usage Alert feature added, allowing customers to set a monthly usage threshold on their account along with a list of email addresses to be notified when that monthly threshold has been exceeded. This feature can be enabled by clicking “Set up alerts” on the “Developers” tab in the Dashboard.
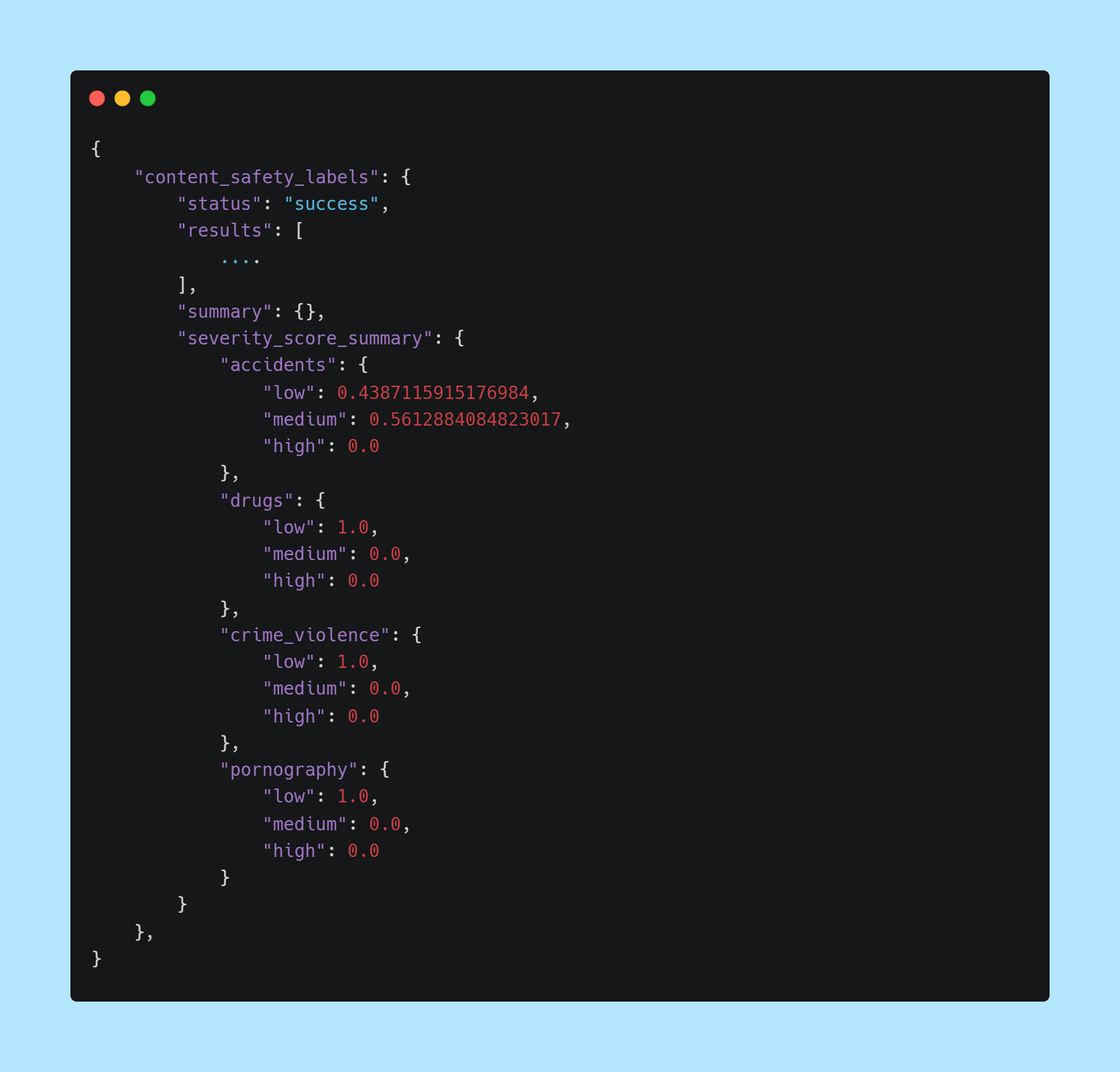
When Content Safety is enabled, a summary of the severity scores detected will now be returned in the API response under the severity_score_summary nested inside of the content_safety_labels key, as shown below.
Improved Filler Word (aka, disfluencies) detection by ~25%.
Fixed a bug in Auto Chapters that would occasionally add an extra space between sentences for headlines and summaries.
1
Entity Detection Released, Improved Filler Word Detection, Usage Alerts
v1 release of Entity Detection - automatically detects a wide range of entities like person and company names, emails, addresses, dates, locations, events, and more.
To include Entity Detection in your transcript, set entity_detection to true in your POST request to /v2/transcript.
When your transcript is complete, you will see an entities key towards the bottom of the JSON response containing the entities detected, as shown here:
Usage Alert feature added, allowing customers to set a monthly usage threshold on their account along with a list of email addresses to be notified when that monthly threshold has been exceeded. This feature can be enabled by clicking “Set up alerts” on the “Developers” tab in the Dashboard.
When Content Safety is enabled, a summary of the severity scores detected will now be returned in the API response under the severity_score_summary nested inside of the content_safety_labels key, as shown below.
Improved Filler Word (aka, disfluencies) detection by ~25%.
Fixed a bug in Auto Chapters that would occasionally add an extra space between sentences for headlines and summaries.
1
Additional MIME Type Detection Added for OPUS Files
Added additional MIME type detection to detect a wider variety of OPUS files.
Fixed an issue with word timing calculations that caused issues with speaker labeling for a small number of transcripts.
1
Additional MIME Type Detection Added for OPUS Files
Added additional MIME type detection to detect a wider variety of OPUS files.
Fixed an issue with word timing calculations that caused issues with speaker labeling for a small number of transcripts.
1
Custom Vocabulary Accuracy Significantly Improved
Significantly improved the accuracy of Custom Vocabulary, and the impact of the boost_param field to control the weight for Custom Vocabulary.